


Das rasante Wachstum der künstlichen Intelligenz ist nicht nur durch komplexe Modelle geprägt, sondern auch durch eine stetige Verlagerung der Rechenarbeit.

SVP AI & UX Development
Während sich in den vergangenen Jahren viele Anwendungen auf die Rechenzentren großer Cloud‑Anbieter stützten, führen Innovationen der Hardware und Verfahren zur Modellkomprimierung dazu, dass immer mehr Aufgaben direkt auf den Geräten ausgeführt werden. Dieses Whitepaper beschreibt die wichtigsten technologischen und ökonomischen Triebkräfte dieser Entwicklung, gibt einen Überblick über die zugrunde liegenden Konzepte und erläutert die Auswirkungen für Unternehmen, Investoren und Entwickler.
Aufstieg spezialisierter KI‑Hardware
Neurorechner und Chips für lokale KI
Hersteller von Prozessoren integrieren seit einigen Jahren dedizierte Beschleuniger, um neuronale Netze effizienter auszuführen. Apple führt dieses Feld mit der M‑Serie an: Der im Frühjahr 2024 vorgestellte M4‑Prozessor enthält eine „Neural Engine“, die laut dem Unternehmen bis zu 38 Billionen Rechenoperationen pro Sekunde ermöglicht, wodurch er mehr Rechenleistung als die NPUs vieler KI‑PCs bietet[1]. Diese spezielle Einheit unterstützt neben klassischen CPU‑ und GPU‑Kernen auch maschinelle Lernfunktionen und sorgt zusammen mit schnelleren Speichern dafür, dass der Chip für Anwendungen der künstlichen Intelligenz besonders geeignet ist[1]. Solche integrierten Beschleuniger sind nicht nur in Tablets und Smartphones zu finden, sondern zunehmend auch in Notebooks und Desktop‑Systemen.
Ein Blick auf den Markt für Edge‑Chips zeigt einen deutlichen Leistungszuwachs. Eine Analyse der Rechercheplattform AIMultiple listet verschiedene Edge‑Prozessoren mit ihren maximalen Rechenleistungen (TOPS). Der Jetson Orin erreicht laut dieser Übersicht bis zu 275 TOPS, während Googles Edge TPU und Intels Movidius Myriad X jeweils vier TOPS liefern. Spezialisierte Chips wie der Hailo 8 bringen 26 TOPS bei sehr geringem Energieverbrauch, und Qualcomms Cloud AI 100 Pro kann je nach Ausbaustufe bis zu 400 TOPS bereitstellen[2]. Diese hohe Rechenkapazität, kombiniert mit niedrigen Wattzahlen, erleichtert den Einsatz anspruchsvoller Modelle auf Robotern, Kameras oder Fahrzeugen.
Vom Datenzentrum zurück zum Gerät
Die stärkeren Chips werden durch fortschrittliche Fertigungsverfahren und optimierte Architekturen möglich. Im Vergleich zu Vorgängergenerationen kann der M4 Prozessor dank einer feineren Strukturbreite und effizienteren Speicheranbindung eine höhere Leistung pro Watt liefern. Auch andere Hersteller verfolgen ähnliche Strategien: Intels kommende Lunar‑Lake‑Plattform soll über 100 TOPS an AI‑Leistung verfügen, wobei ein großer Anteil direkt von der NPU stammt. In Kombination mit modernen Funktechnologien wie 5G sinkt die Latenz zwischen Sensordaten und Auswertung, sodass Echtzeitanwendungen im industriellen Umfeld möglich werden. Die Integration solcher Chips in PCs führt zu einer neuen Geräteklasse, die Microsoft als „Copilot PC“ bewirbt, weil sie generative Funktionen offline durchführen können.
Konzepte und Verfahren lokalisierter Modelle
Warum Komprimierung notwendig ist
Ein großes Hindernis für lokale KI‑Anwendungen ist die Größe aktueller Modelle. Viele generative Sprachmodelle bestehen aus mehreren Milliarden Parametern, was erheblichen Speicherbedarf und hohe Rechenleistung erfordert. Eine aktuelle wissenschaftliche Untersuchung hebt hervor, dass die Verlagerung von KI‑Modellen auf das Edge durch drei Optimierungsbereiche ermöglicht wird: Daten‑Optimierung, Modell‑Optimierung und System‑Optimierung[3]. Die Autoren betonen, dass die zunehmende Datenmenge auf Endgeräten und der Bedarf an lokaler Verarbeitung effiziente Modelle erforderlich machen[3].
Methoden der Modelloptimierung
Um Modelle für Geräte mit eingeschränkten Ressourcen anzupassen, nutzen Entwickler zwei Ansätze: das Entwerfen von kompakten Architekturen und die Modellkomprimierung. Kompakte Architekturen wie MobileNets oder EfficientNet werden bereits bei der Entwicklung auf Effizienz getrimmt und liefern bei minimalem Parameterumfang solide Ergebnisse in mobilen Vision‑Anwendungen[4]. Zusätzlich lassen sich bestehende Modelle durch Komprimierung verkleinern. Die in der zitierten Studie beschriebenen Verfahren umfassen das Entfernen irrelevanter Gewichte (Pruning), das Teilen von Parametern, die Reduzierung der Genauigkeit durch Quantisierung, das Übertragen von Wissen eines großen Modells auf ein kleineres per „Knowledge Distillation“ sowie niedrigrangige Faktorisierung[5]. Durch die Kombination dieser Techniken lassen sich neuronale Netze deutlich schrumpfen, ohne die Genauigkeit stark zu beeinträchtigen[6]. Die Autoren führen zudem Beispiele wie „Deep Compression“ an, bei denen mehrere Methoden gleichzeitig angewendet werden, um den Speicherbedarf von Netzwerken massiv zu senken[7].
Leichte multimodale Modelle
Ein wichtiger Trend besteht darin, dass multimodale Modelle auf dem Gerät laufen können. Das Team hinter dem Modell Octopus v3 stellt in seinem technischen Bericht ein kompakt gehaltenes multimodales Netzwerk vor, das mit weniger als einer Milliarde Parametern auskommt und dank spezieller „Functional Tokens“ sowohl Sprache als auch Bilder verarbeiten kann[8]. Wegen seiner geringen Größe funktioniert das Modell auf Geräten mit begrenztem Arbeitsspeicher wie einem Raspberry Pi [8]. Solche Entwicklungen zeigen, dass generative und multimodale Fähigkeiten nicht zwingend an große Cloud‑Infrastrukturen gebunden sind.
Use Cases und neue Produktklassen
Autonome Systeme und smarte Fabriken
Edge‑KI kommt dort zum Einsatz, wo geringe Verzögerung und Unabhängigkeit vom Netz gefragt sind. Die erwähnte Edge‑AI‑Studie nennt als typische Anwendungen autonome Fahrzeuge, Virtual‑Reality‑Spiele, smarte Fabriken, Überwachungskameras und tragbare Gesundheitsgeräte[9]. Durch die unmittelbare Verarbeitung der Sensordaten können autonome Fahrzeuge rasch reagieren, während smarte Fabriken flexible Produktionsprozesse realisieren. Wearables analysieren Vitaldaten ohne stetige Verbindung zum Internet und bieten trotzdem personalisierte Auswertungen.
Edge‑AI‑Devices wie MAVERICKAI
Eine besondere Innovation stellt der von AMERIA entwickelte Laptop MAVERICKAI dar. Das Gerät ist ein revolutionärer Laptop, der künstliche Intelligenz für jeden zugänglich macht. Es vereint eine persönliche Assistenzfunktion und eine Plattform zur Interaktion mit dreidimensionalen Inhalten, ohne dass zusätzliche Geräte wie VR‑Brillen nötig sind[10]. Die Nutzerinnen und Nutzer können per Spracheingabe mit dem integrierten Assistenten kommunizieren. Das System orchestriert mehrere KI‑Dienste im Hintergrund [11]. Dank einer Erkennung von Bewegungen und Gegenständen im dreidimensionalen Raum lässt sich das Gerät ohne Tastatur oder Maus bedienen. Die Benutzeroberfläche, die sowohl privat als auch im Berufsalltag genutzt werden kann, wird so vollkommen virtualisiert [12]. Sogar chirurgische Eingriffe können zukünftig durch Integration des Laptops mit OP‑Daten unterstützt werden [13]. Diese Beispiele zeigen, dass innovative Hardware gepaart mit lokaler Intelligenz völlig neue Produktkategorien hervorbringt.
Industriebeispiele für multimodale On‑Device‑Modelle
Die zunehmende Leistungsfähigkeit kompakter Modelle ermöglicht weitere Demonstrationen. Das Octopus‑v3‑Modell, das wie oben erwähnt auf kleinen Geräten läuft, veranschaulicht, wie multimodale Agenten Aufgaben ausführen können, die bisher großen LLMs vorbehalten waren. Weitere Ankündigungen, etwa von Google und Qualcomm, zeigen, dass Smartphones und PCs bald multimodale Eingaben wie Text, Bilder und Audio lokal verarbeiten. Diese Fähigkeiten ebnen den Weg für Anwendungen wie erweiterte persönliche Assistenten, übersetzende Augmented‑Reality‑Brillen und intelligente Robotics‑Systeme.
Auswirkungen auf Infrastruktur, Geschäftsmodelle und Datenschutz
Veränderte Cloud‑Infrastruktur
Wenn mehr Daten lokal verarbeitet werden, verringert sich der Bedarf an der ständigen Verbindung mit Cloud‑Rechenzentren. Die zitierten Edge‑Forschungsberichte heben hervor, dass die lokale Ausführung zu schnelleren Entscheidungen, geringerem Bandbreitenverbrauch und verbesserter Zuverlässigkeit führt [9]. Gleichzeitig entstehen neue Herausforderungen: Modelle müssen verteilt verwaltet werden, die Einbindung in unternehmensweite Architekturen erfordert ausgefeilte Platzierung, Migration und Skalierungsstrategien [14]. Trotz der Verlagerung wird eine enge Verzahnung von Cloud‑ und Edge‑Systemen nötig bleiben, um Trainingsdaten zu aggregieren, Updates auszurollen und Lastspitzen abzufedern.
Sicherheit und Privatsphäre
Mit der Verarbeitung sensibler Daten auf Geräten steigen die Anforderungen an Schutzmechanismen. Laut dem Edge‑AI‑Survey erfordert die verteilte Natur von Edge‑Computing neue Sicherheitskonzepte. Vorgeschlagen werden Daten‑Anonymisierung, vertrauenswürdige Ausführungsumgebungen, homomorphe Verschlüsselung und sichere Mehrparteienberechnung [15]. Federated Learning ist ein weiteres Schlüsselkonzept: Modelle werden auf einer Vielzahl von Geräten trainiert, ohne dass Rohdaten das Gerät verlassen [16]. Künftig könnten auch Blockchain‑Technologien eingesetzt werden, um den Austausch und die Auswertung von Daten dezentral und manipulationssicher zu gestalten [17].
Wirtschaftliche Implikationen
Die Verlagerung der Intelligenz auf das Gerät selbst verändert Geschäftsmodelle. Hersteller von Halbleitern profitieren von der Nachfrage nach spezialisierten Prozessoren und NPUs. Anbieter von Cloud‑Diensten müssen ihre Rolle neu definieren und zusätzliche Edge‑Services anbieten. Gleichzeitig ergeben sich neue Einnahmequellen im Bereich auf Hardware basierender Abonnement‑Modelle, bei denen Software‑Funktionen an bestimmte Chips gebunden sind. Für Endanwender entstehen Vorteile durch geringere Latenzen und eine verbesserte Verfügbarkeit. Unternehmen können strengere Datenschutzanforderungen erfüllen und lokale Compliance‑Regeln besser einhalten.
Empfehlungen für Entscheidungsträger und Investoren
Pilotprojekte zur Edge‑KI
Unternehmen sollten frühzeitig Pilotprojekte initiieren, um Erfahrungen mit Edge‑Technologien zu sammeln. Einsatzgebiete mit hohen Latenzanforderungen wie die Qualitätskontrolle in der Produktion oder autonome Logistik eignen sich besonders. Es empfiehlt sich, zunächst kleine, abgeschlossene Aufgaben zu wählen und die Ergebnisse systematisch zu analysieren. Investitionen in Know‑how zu Quantisierung, Distillation und anderen Komprimierungsverfahren sind notwendig, um eigene Modelle erfolgreich anzupassen.
Auswahl passender Hardware
Bei der Wahl der Hardware sollte nicht nur auf die Gesamt‑TOPS geachtet werden, sondern auch auf Energieeffizienz, Unterstützung durch Software‑Stacks und Verfügbarkeit. Der Jetson Orin ist etwa für Robotik und autonome Systeme konzipiert und bietet bis zu 275 TOPS bei 10–60 Watt. Googles Edge TPU eignet sich für IoT‑Anwendungen mit sehr geringem Energieverbrauch, während der Hailo 8 eine gute Balance aus Leistung und Effizienz für Smart‑Kameras liefert [18]. Für hochperformante Szenarien können Unternehmen auf Chips wie den Cloud AI 100 Pro von Qualcomm zurückgreifen, der bis zu 400 TOPS erreicht [18]. Es ist wichtig, die Software‑Ökosysteme der Anbieter und die Unterstützung von Frameworks wie PyTorch Mobile oder TensorFlow Lite zu berücksichtigen.
Infrastruktur und Sicherheit planen
Edge‑Projekte erfordern eine sorgfältige Planung der Infrastruktur. Dies umfasst das Management verteilter Modelle, Mechanismen zur Modell‑Aktualisierung über unsichere Netze und Strategien zur Migration zwischen Knoten [14]. Zudem sollten Unternehmen frühzeitig in Sicherheitsmechanismen investieren, beispielsweise vertrauenswürdige Ausführungsumgebungen oder homomorphe Verschlüsselung [15]. Die Implementierung von Federated Learning kann helfen, Datenschutzvorgaben einzuhalten und gleichzeitig von verteilten Daten zu profitieren [16].
Ausblick für Investoren
Investoren im Halbleiter‑ und Infrastrukturbereich sollten die Marktchancen im Edge‑Segment genau beobachten. Die Nachfrage nach NPU‑fähigen Prozessoren wird durch neue Produktkategorien wie MAVERICKAI und durch Anwendungen in der Industrie steigen. Beteiligungen an Herstellern von Energiesparchips, Software‑Anbietern für Modellkomprimierung und Unternehmen mit Know‑how in Federated‑Learning‑Plattformen könnten sich auszahlen. Zudem lohnt sich ein Blick auf Start‑ups, die multimodale Modelle speziell für den Einsatz auf Edge‑Geräten entwickeln, wie die in Octopus v3 dargestellte Forschung[8].
Fazit
Der Trend zur lokalen Verarbeitung von KI‑Modellen ist unübersehbar. Fortschritte bei spezialisierten Chips, die Hunderte von TOPS liefern, und Verfahren zur Reduktion der Modellgröße ermöglichen es, anspruchsvolle Anwendungen ohne dauerhafte Cloud‑Anbindung zu betreiben. Produkte wie MAVERICKAI und Forschungsergebnisse zu multimodalen Kompaktmodellen belegen, dass sich neue Märkte und Nutzungsszenarien eröffnen. Für Unternehmen bedeutet diese Entwicklung sowohl Chancen als auch Herausforderungen: Sie können datenschutzfreundliche und latenzarme Dienste anbieten, müssen aber zugleich in Hardware, Modelloptimierung und Sicherheitsmaßnahmen investieren. Investoren profitieren von wachsender Nachfrage im Halbleitersektor und von neuen Geschäftsmodellen, die aus der zunehmenden Autarkie der Geräte entstehen. Die Zukunft der künstlichen Intelligenz wird damit stärker dezentral geprägt sein.
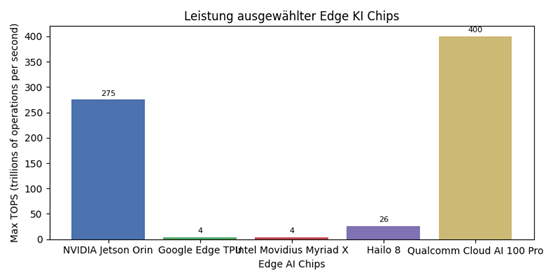
Abb. 1: Vergleich der maximalen Rechenleistung ausgewählter Edge‑Chips. Daten nach AIMultiple Research 2025 [2].
[1] Apple introduces M4 chip - Apple
https://www.apple.com/newsroom/2024/05/apple-introduces-m4-chip/
[2] [18] Top 20 AI Chip Makers: NVIDIA & Its Competitors in 2025
https://research.aimultiple.com/ai-chip-makers/
[3] [4] [5] [6] [7] [9] [14] [15] [16] [17] Optimizing Edge AI: A Comprehensive Survey on Data, Model, and System Strategies
https://arxiv.org/html/2501.03265v1
[8] Paper page - Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent
https://huggingface.co/papers/2404.11459
[10] [11] [12] [13] AMERIA AG | MAVERICK AI | Our journey towards a Touchfree future for everyone.
https://www.ameria.com/maverickai
Teile diesen Artikel



AMERIA ist ein führendes europäisches Deep-Tech-Unternehmen mit Sitz in Heidelberg, das die Zukunft der Mensch-Maschine-Interaktion durch bahnbrechende digitale Technologien gestaltet. Mit MAVERICKAI entwickelt AMERIA das erste echte KI-Device, das auf einer Laptop-Plattform aufgebaut ist – eine Kombination aus intelligenter Software, einem revolutionären KI-Assistenten und einem schlanken Formfaktor.
Aktuelle Neuigkeiten und Presseartikel



.jpg)



Kontaktieren Sie unser Presseteam.
AMERIA ist ein führendes europäisches Deep-Tech-Unternehmen mit Sitz in Heidelberg, das die Zukunft der Mensch-Maschine-Interaktion durch bahnbrechende digitale Technologien gestaltet. Mit MAVERICKAI entwickelt AMERIA das erste echte KI-Device, das auf einer Laptop-Plattform aufgebaut ist – eine Kombination aus intelligenter Software, einem revolutionären KI-Assistenten und einem schlanken Formfaktor.